Das Bakterium Esherichia coli ist der am gründlichsten erforschte einzellige Organismus in der Welt. Wie komplex ist es? Was brauchte man, um es zu erdenken und es zu machen? Wie lang ist sein Genom (DNA-Strang)? Wie viel Protein und tRNA enthalten seine Ribosome, seine Proteinfabriken? Und wie komplex sind seine Enzyme?
Es kann gut sein, dass Sie, geehrter Leser, einige oder sogar die meisten der technischen Details nicht verstehen. Machen Sie sich deswegen keine Sorgen. Sogar die führenden Mikrobiologen der Welt verstehen das nur etwas. Vieles davon haben sie überhaupt noch nicht verstanden. Das zeigt Ihnen nur um so deutlicher, wie viel die winzige Zelle über Wissenschaft wissen muss. Und Sie mögen sich dann fragen: Warum weiß das Bakterium das alles über Physik, Chemie und Mikrobiologie?
Frederic C. Neidhardt, Universität von Michigan, Ann Arbor, John L., Ingraham, Universität von Kalifornien Davis, und Moselio Schaechter, Tufts-Universität, Boston, schreiben in ihrem Lehrbuch, Physiology of the Bacterial Cell (1990:14):
"Man kennt jetzt das vollständige, einzelne Chromosom von E. coli recht genau. Es ist ein kreisförmiges, doppelt-fädiges Molekül von 4.720.000 Basenpaaren (4.720 Kilobasenpaaren oder kbp gekürzt. Deshalb beträgt sein molekulares Gewicht etwa 2,5·109. Und wenn ausgestreckt, ist es ist ungefähr 1 mm lang. Wie so eine Struktur in die Zelle hinein passt, die nur 1/500 seiner Länge ist, ist eine interessante Geschichte.
"Was können 4.20 kbp für eine Zelle tun? Das durchschnittliche molekulare Gewicht der E. coli Proteine ist 40.000. Und das durchschnittliche molekulare Gewicht eines Aminosäure-Rückstandes im Protein, ist 110. Deshalb hat das durchschnittliche Protein 364 Aminosäuren. Man braucht drei Nukleotid-Basen in der DNA, um jeden Aminosäure-Rückstand in einem Protein zu bestimmen. Deshalb hat die durchschnittliche Gengrösse in E. coli ungefähr 1,1 kbp... Vernünftige Korrekturen für DNA, die kein Protein verschlüsselt, zeigen uns, dass es etwa 3.800 Protein codierende Gene enthält."
Frederick R. Blattner und Mitarbeiter haben die vollständige Genom-Reihenfolge von Escherichia coli K-12 erforscht. Sie berichten über ihre Ergebnisse in Science, Band 277, 5 September1997 S. 1453: Escherichia coli K-12 hat eine Genom-Länge von 4.639.221 Basenpaaren. Escherichia coli ist ein wichtiger Bestandteil der Biosphäre. Es lebt im Dickdarm von Tieren. Es ist fakultativ anaerob und überlebt, wenn das Tier es in die natürliche Umwelt ausscheidet. Es kann sich deshalb weit ausbreiten und sich (im Dickdarm) anderer Tiere einnisten. Wie viel Information braucht man, um die Basenpaare dieses DNA-Stranges an die richtige Stelle zu setzen?
4.639.221 bp log 4 = 102.793.089 Bit. So viel Information braucht man, um die Basenpaare seines DNA-Stranges an die richtige Stelle zu setzen.
Das Ribosom: Seine RNA und Proteine
Was haben Wissenschaftler jetzt über das Ribosom des Bakteriums E. coli herausgefunden? Warum gibt es das? Wie funktioniert es? Und wie komplex ist es?
James D. Watson und Mitarbeiter: "Sobald die Aminosäuren ihre Anpassungsvorrichtungen erworben haben, wandern sie zu den Ribosomen. Die kann man als kleine Fabriken betrachten, die Proteine herstellen. Ihre Hauptaufgabe besteht darin, die ankommenden AA-tRNA-Vorläufer und die Schablonen-RNA richtig hinzulegen, damit der genetische Code richtig gelesen werden kann. Ribosome enthalten bestimmte Oberflächen. Sie binden die Schablonen-RNA, die AA-tRNA-Vorläufer und die wachsende Polypeptid-Kette und stellen sie in geeignete stereochemische Positionen auf.
"Es gibt in einer schnell wachsenden E. coli Zelle ungefähr 15.000 Ribosome. Jedes Ribosom hat ein molekulares Gewicht von etwas weniger als 3 Millionen Dalton. Alle Ribosome zusammen machen etwa ein Viertel der gesamten bakteriellen Zellenmasse aus. Ein recht großer Teil der gesamten zellularen Synthese dient daher dazu, Ribosome herzustellen. Das einzelne Ribosom kann nur eine Polypeptid-Kette auf einmal herstellen. Unter optimalen Bedingungen dauert es etwa 10 Sekunden, um eine Kette von 400 Aminosäuren (molekulares Gewicht von etwa 40.000) herzustellen. Die fertige Polypeptid-Kette wird dann frei gelassen. Und das freie Ribosom kann sofort wieder das nächste Protein herstellen.
"Alle Ribosome bestehen aus zwei Untereinheiten, die größere Untereinheit ist ungefähr doppelt so groß wie die kleinere. Beide Untereinheiten enthalten sowohl RNA als auch Protein. In bakteriellen Ribosomen, beträgt das Verhältnis von RNA und Protein etwa 2:1; in vielen anderen Organismen ist es etwa 1:1. Beide großen und kleinen Untereinheiten enthalten eine große Anzahl verschiedener Proteine. Man hat die ribosomalen Proteinen von E. coli intensiv untersucht.
"Die 21S Proteine (S1 bis S21) der kleineren (30SI) Untereinheit sind verschieden groß. Vor kurzem hat man sie alle sequenziert. Und es ist klar geworden, dass jedes nur in einer Kopie je Ribosom vorhanden ist. Auch die meisten 34L Proteine (L1 toL34) in der größeren (50S) Untereinheit, sind nur jeweils einmal in einem bestimmten Ribosom vorhanden." Watson, J. D. et al. (1987:393).
"Meistens verringert sich die Größe des Proteins, je mehr davon da sind. Das heißt, S1 ist das größte Protein (MW etwa 60.000) und S21 ist das kleinste Protein (MW etwa 8.000) auf dem 30S Ribosom, und L1 ist das größte Protein (MW etwa 25.000) und L34 das kleinste Protein (MW etwa 5.000) auf dem 50S Ribosom." (1987:394). (MW = Molekulargewicht)
Ribosomale RNA, in drei Größen
Die RNA im Ribosom gibt es in drei grundlegenden Größen. Wie groß sind diese Ketten? Und wie viele Nukleotide haben sie?
James D. Watson und Mitarbeiter: "Zwei große tRNA-Moleküle und ein kleines tRNA-Molekül gibt es in jedem bakteriellen Ribosom. Sie sind wesentliche Bestandteile. Und im Gegensatz zur mRNA, kann man sie nicht entfernen, weil dann die Ribosom-Struktur völlig in sich zusammen stürzt. Das 16S rRNA-Molekül, das man in der kleineren ribosomalen Untereinheit findet, hat eine Kettenlänge von 1.542 Nukleotiden. Während das 23S Molekül, ein Bestandteil der größeren ribosomalen Untereinheit, 2.904 Nukleotide enthält. Jede größere Untereinheit enthält außerdem ein sehr kurzes rRNA-Molekül. Es sedimentiert bei 5S und hat 120 Nukleotide. Alle drei tRNAs bestehen aus einem Strang. Und sie haben ungleiche Mengen von Guanin und Cytosin und von Adenin und Uracil.
"Trotz dieser RNA-RNA Wechselwirkungen sind wir noch weit davon entfernt, zu verstehen, was die Hunderte von ungepaarten Nukleotiden jedes rRNA-Bestandteiles genau machen. ... Die 16S, 23S und 5S rRNAs werden in dieser Reihenfolge in einer einzigen 30S-tRNA Abschrift von etwa 6.500 Nukleotiden kopiert. ... Bei der vor-rRNA ist es eindeutig von Vorteil, die 6S und 5S Sequenzen in einer einzigen Abschrift zusammenzufassen, um sicherzustellen, dass dann von den drei Molekülen gleich viele vorhanden sind, wenn das Ribosom zusammengebaut wird." (1987:395-400).
Boten-RNA
Was ist Boten-RNA? Was macht es in der Zelle? Und wie komplex ist es?
James D. Watson und Mitarbeiter: "Diese RNA bindet sich umkehrbar an die Oberfläche der kleineren ribosomalen Untereinheit... Es trägt die genetische Mitteilung vom Gen zu den ribosomalen Fabriken. Deshalb nennt man diese RNA Boten-RNA (mRNA). Das mRNA bewegt sich durch das Ribosom, wo das Protein hergestellt wird. Das mRNA bringt die aufeinanderfolgenden Codon in die richtige Position, um die geeigneten AA-rRNA Vorläufer auszuwählen.
"Die tRNA-Moleküle haben ein molekulares Gewicht von etwa 2,5·104. Und die rRNA-Moleküle haben ein Molekulargewicht von (4·104, 5·105 und 106 für 5S, 16S, und 23S). Die mRNA-Moleküle variieren dagegen sehr in ihrer Kettenlänge und daher auch in ihrem molekularen Gewicht. ... Die meisten Polypeptid-Ketten enthalten 100 oder mehr Aminosäuren. Und deshalb müssen die meisten mRNA-Moleküle mindestens 100 x 3 Nukleotide enthalten (weil es drei Nukleotide in einem Codon gibt). ... In E. coli enthalten deshalb die mRNAs, welche die durchschnittlichen großen Polypeptide von 300 bis 500 Aminosäuren codieren, gewöhnlich 1.000 bis 2.000 Nukleotide.
"Ein einzelnes mRNA-Molekül, zum Beispiel, codiert fünf bestimmte Enzyme, die man braucht, um die Aminosäure Tryptophan zusammenzufügen. Man hat es kürzlich vollständig sequenziert. Es enthält etwa 6.800 Nukleotide oder durchschnittlich 1.400 Nukleotide, die jedes Enzym und seine benachbarten intergenischen Gebiete codieren." (1987:395, 404, 406).
"Am besten kennt man ein Enzym namens Ribonuclease P (PNase P). Es entfernt die zusätzlichen 5´ Nukleotide. ... Als man die Rnase P reinigte, erkannte man, dass dieses Enzym kein reines Protein ist. Es ist ein nichtkovalenter Komplex von einem kleinen RNA Molekül. Es ist 377 Rückstände lang und enthält ein kleines Protein (MW etwa 20.000). Wiederherstellungs-Untersuchungen, sowie die Identifikation von Mutanten in der RNA und im Protein haben gezeigt, dass beide Bestandteile zur Rnase P Aktivität unter physiologischen Zuständen beitragen." Watson, J. D. et al. (1987:402).
Die Zelle: Ihr Informationsgehalt
Wie viel Information enthält eine bakterielle Zelle, wie Escherichia coli, zum Beispiel? Mit anderen Worten: Was brauchte man, um sie auszudenken und sie zu machen? Die Stränge von DNA, RNA und Protein in der Zelle sind wie der geschriebene Text in einem Buch, mit seinen Buchstaben, Sätzen und Kapiteln. Nehmen wir einen einfachen Satz aus einem Telegramm, als ein Beispiel:
I HAVE RECEIVED NOW THE BOOKS
(Ich habe jetzt die Bücher bekommen)
Wie viel Information enthält dieser Satz? Das Alphabet der englischen Sprache enthält 27 Zeichen (26 Buchstaben und 1 Leerzeichen). Deshalb hat jeder Buchstabe 4,05 Bit (Gitt, W. 1986:64). Dieser Satz hat 24 Buchstaben und 5 Leerzeichen: 29 Zeichen in einem Alphabet von 27 Zeichen. 29 x 4.05 Bit/Buchstabe = 117,45 Bit statistische Information. – Wie viel statistische Information wird dieser Satz haben, wenn wir sie alle umstellen, sie durcheinander bringen?
WERHA VOIN EKN VBEOC IESD OTE
Der Satz, mit seinen 29 Zeichen, enthält immer noch eine statistische Information von 117.45 Bit. Aber er bedeutet nichts mehr. Deshalb müssen wir uns jetzt fragen: Wie viel Information braucht man, um die 29 Zeichen dieses Satzes richtig zu ordnen? Mit anderen Worten: Was sind seine Reihenfolge-Alternativen? -29 Zeichen log 27 = 41,5 = 1041. Das bedeutet: 1041 ja/nein Entscheidungen (oder Reihenfolge-Alternativen) brauchen wir jetzt, um diese 29 Zeichen an die richtige Stelle zu setzen. 1041 ja/nein Entscheidungen sind 1041 Bit Information. Was bedeutet das? Wie viel Information ist das?
Alles Wissen, das der Mensch bis jetzt in Büchern aufgeschrieben hat, enthält 1018 Bit Information. 1041 : 1018 = 1·102. Das bedeutet: Die Information, die in den Reihenfolge-Alternativen dieses einfachen Satzes enthalten ist, ist 1023 Male größer, als alles Wissen, das der Mensch bis jetzt in Büchern aufgeschrieben hat. Dies wird uns helfen, herauszufinden, ob sich das Leben auf Erde von selbst in der "chemischen Ursuppe" aus anorganischer Materie entwickeln konnte.
Escherichia coli, Ja/Nein Entscheidungen
Wie viele ja/nein-Entscheidungen braucht man für die DNA, RNA und Proteinketten in der bakteriellen Zelle Escherichia coli? Was sind ihre Reihenfolge-Alternativen? Wie viel Information brauchte man, um sie richtig zu ordnen? Das wird uns auch helfen, herauszufinden, ob der sogenannte "16S-rRNA phylogenetische Baum des Lebens" Wissenschaft ist oder nur Science-Fiction.
Das Genom (DNA-Strang) von E. coli hat 4.720.000 Basenpaare. Der DNA-Code hat 4 Buchstaben (Nukleotide). Und man braucht 3 Nukleotid-Basen der DNA, um jeden Aminosäure-Rückstand in einem Protein zu bestimmen (Neidhardt, F. D. et al. 1990:14). 4.720.000 bp DNA log 4 = 102.841.723 Bit.
Die meiste genetische Information der bakteriellen Zelle ist auf seinem Genom (DNA-Strang) codiert (aufgeschrieben und gespeichert). Deshalb braucht man 102.841.723 Bit Information, um diese 4.720000 DNA Buchstaben richtig zu ordnen. Alles Wissen, das der Mensch bis jetzt in Büchern aufgeschrieben, enthält nur 1018 Bit!
Man muss ein geschulter Mikrobiologe oder Molekularbiologe sein, um das Genom der Zelle etwas zu verstehen und damit zu arbeiten. Aber kein Wissenschaftler konnte bis jetzt den ganzen DNA Strang (Genom) von Escherichia-coli herstellen, weil das viel zu kompliziert ist. Deshalb muss derjenige, der die ganze lebende Zelle, mit ihrem Genom, erdacht und gemacht hat, viel mehr wissen, als ein hoch qualifizierter menschlicher Mikrobiologe. Ein Affe kann nicht als Mikrobiologe arbeiten. Er weiß zu wenig.
Das menschliche Genom hat etwa 3.500.000.000 Basenpaare. Wie viel Information braucht man, um sie an die richtige Stelle zu setzen? 3.500.000.000 bp log 4 = 102.107.209.970 Bit.
Das bedeutet: Das menschliche Genom, mit seinen 3,5 Milliarden Basenpaaren, hat mindestens 102.107.209.970 Bit Information oder ja/nein Entscheidungen. Eine intelligente Person musste diese genetische Information erst erdenken und sie dann machen: Gott.
Evolutionärer Baum des Lebens
Der 16S rRNA phylogenetische Baum des Lebens soll beweisen, dass sich alles Leben auf Erde aus einem gemeinsamen Vorfahren entwickelt hat, aus der ersten einfachen Zelle. Und diese erste einfache Zelle soll sich in der "chemischen Ursuppe" aus anorganischer Materie entwickelt haben. Es gibt im bakteriellen Ribosom drei verschiedene Arten von rRNA-Ketten: 16S, 23S, und 5S. Diese ribosomalen RNA Ketten bestehen aus einzelnen Strängen. Und sie sind mit den Proteinen des Ribosoms verwoben. Es gibt in der kleinen Untereinheit des Ribosoms 21 verschiedene Arten von Proteinen (S1-S21), und in der großen Untereinheit des Ribosoms (L1-L34) 34 Proteine. - Wie groß sind sie? Und wie viel Information enthalten sie? Wie sind sie entstanden?
16S rRNA. Das 16S rRNA-Molekül ist eine Kette von 1.542 Nukleotiden. Wie viel Information braucht man, um sie richtig zu ordnen? 1.542 rRNA-Nukleotide log 4 = 10928 Bit.
Das bedeutet: Man braucht mindestens 10928 Bit Information (ja/nein Entscheidungen), um das 16S rRNA-Molekül des Bakteriums zu E. coli zu machen.
23S rRNA. Das 23S rRNA-Molekül hat 2.904 Nukleotide. Wenigstens 101.748 ja/nein Entscheidungen (oder Bit Information) braucht man, um es zu machen.
5S rRNA. Das 5S rRNA-Molekül hat 120 Nukleotide. Man braucht 1072 ja/nein Entscheidungen (oder Bit Information), um es zu machen.
"Die 16S, 23S und 5S rRNAs werden in dieser Reihenfolge in einer einzigen 30S Vor-rRNA Abschrift von etwa 6.500 Nukleotiden abgeschrieben", berichten James D. Watson und Mitarbeiter (1987:400). So entstehen die 3 Moleküle in der gleichen Menge. - Was braucht man, damit diese vereinte Kette von 6.500 rRNA-Nukleotiden entstehen kann? Sie enthält 103.913 Reihenfolge-Alternativen oder Bit Information. Das widerlegt eindeutig den Glauben an den 16S rRNA phylogenetischen Baum des Lebens: dass sich alles Leben auf Erde aus der ersten Urzelle entwickelt hat. Das ist nur Science-Fiction.
Ribosomale Proteine
Das größte Protein auf dem 30S Ribosom, S1, hat ein molekulares Gewicht von 60.000. - Wie viele Aminosäuren sind das? Wie viel Information hat man gebraucht, um sie an die richtige Stelle zu setzen? Und wie viel DNA brauchte man, um, dieses Protein zu machen?
1 Aminosäure hat ein molekulares Gewicht von 110. Und 60.000 MW : 110 MW = 545 Aminosäuren. 545 log 20 = 10709. Der Proteincode hat ein Alphabet von 20 Buchstaben (Aminosäuren). Man braucht drei bestimmte Nukleotide, um 1 Aminosäure zu machen. 545 x 3 = 1.635 Nukleotide. 1.635 Nukleotide log 4 = 10984. Wir zählen jetzt diese beiden Reihenfolge-Alternativen, 10709 und 10984 zusammen und kommen auf 101.693. Das bedeutet: Mindestens 101.693 Bit Information braucht man, um das größte Protein S1 im 30S Ribosom zu machen. Und im ganzen bakteriellen Ribosom gibt es 55 verschiedene Proteine.
Lösliche Faktoren in E. coli
E. coli enthält auch bestimmte lösliche Faktoren. Die Zelle baut auch diese mit Hilfe der Erbinformation auf. Das sind Proteine, die sie für Anfang (Initiation), Verlängerung und Ende (Termination) braucht. Wie groß sind diese Proteine? - J. D. Watson et al. (1987:413) geben folgende Werte an:
IF1 900 MW, IF2 120.000 MW, IF3 220.000 MW.
Verlängerung: EF-Tu 45.000 MW, EF-Ts 30.000 MW, EF-G 80.000 MW.
Ende: RF1 36.000 MW, RF2 38.000 MW, RF3 46.000 MW.
Brachten wir hier nur kurz ein Beispiel, das IF2, das Protein für den Anfang, mit seinem Molekulargewicht von 120.000. Wie viele Aminosäuren braucht man, um es zu machen? Und wieviel Information braucht man, um diese Aminosäuren richtig zu ordnen? Wieviel DNA braucht man, um dieses Protein IF2 aufzubauen? Und was braucht man, um die Nukleotide dieser DNA richtig zusammen zu stellen, damit der Text sinnvoll wird und seinen Zweck erfüllt?
Anfangs-Protein IF2
Das Anfangs- oder Einleitungsprotein IF2 von E. coli hat ein molekulares Gewicht von 120.000. Eine Aminosäure hat ein molekulares Gewicht von 110. Das sind dann 1.090 Aminosäuren. 1.090 Aminosäuren log 20 = 101.419. –1.090 Aminosäuren x 3 Nukleotide/1 Aminosäure = 4.257 Nukleotide. 4.257 log 4 = 102.563. Wenn wir diese beiden Reihenfolge-Alternativen hinzufügen, bekommen wir eine Gesamtsumme von 103.982. Das bedeutet: Man braucht mindestens 103.982 Bit Information (ja/nein Entscheidungen), um das Anfangsprotein IF2 der bakteriellen Zelle E coli, mit seinem molekularen Gewicht von 120.000 zu machen.
Transport-RNA
Wie komplex ist ein Transport-RNA Molekül (tRNA) in E. coli? Wie groß ist es? - Das tRNA-Molekül hat ein molekulares Gewicht von 2,5·104, gemäß Watson, J. D. et al. (1987:404). Eine Base von DNA oder RNA (1 Nukleotid) hat ein molekulares Gewicht von 330 MW. Das ist halb soviel wie das molekulare Gewicht eines Basenpaares, das 660 MW hat, wie Arthur Kronberg und Tania A. Baker (1992:20) und Christian de Duve (1986) berichten.
2,5·104 MW : 330 MW = 75,75 RNA Nukleotide.
75 RNA Nukleotide log 4 = 1045.
Das bedeutet: 1045 Bit Information braucht man, um ein tRNA-Molekül herzustellen.
.
Boten-RNA
Ein einzelnes mRNA-Molekül codiert 5 bestimmte Enzyme. Sie fügen die Aminosäure Tryptophan zusammen. Es hat 6800 Nukleotide. Jedes Enzym und seine benachbarten intergenetischen Gebiete benötigen 1.400 Nukleotide, gemäß J. D. Watson et al. (1987:406). Was braucht man dann, damit dieses mRNA-Molekül entstehen kann?
6.800 Nukleotide log 4 = 109.094. Und jedes der 5 bestimmten Enzyme, mit je 1.400 Nucleotiden, enthält 10842 Bit Information oder ja/nein Entscheidungen. Das beweist Schöpfung und widerlegt Evolution. Information und Mathematik entstammen immer einer geistigen, nicht-materiellen Welt. Sie sind im Sinn eines intelligenten Wesens entstanden: des Schöpfers.
DNA-Verdoppelung
Wie vervielfältigt sich die lebende Zelle? Und wie genau vervielfältigt sie ihre DNA?
Morislav Radman ist Forschungs-Direktor beim Nationalen Zentrum für Wissenschaftliche Forschung (CNRS) in Paris. Der Amerikaner Robert Wagner hat dort mit ihm zusammen gearbeitet. Sie berichten in ihrem Artikel "Die hohe Wiedergabetreue der DNA-Verdoppelung" in Scientific American, August 1988 Seite 24:
"Alles Leben hängt von der genauen Übermittlung der Information ab. Wenn die genetischen Mitteilungen Generationen von Zellteilungen durchlaufen, können sogar kleine Fehler das Leben bedrohen. Wenn im Menschen ein einziger 'Buchstabe' in der genetischen Mitteilung ausgewechselt wird, kann das eine tödliche Erbkrankheit verursachen, wie zum Beispiel, die Sichelzellenanämie und Thalassemia. Auch mehrere gewöhnliche Krebse entstehen, wenn ein einzelner Buchstabe ausgewechselt wird.
"Für einen Organismus, der so komplex ist wie ein Mensch, ist es schon eine enorme Leistung, genau genug zu arbeiten. Der Satz genetischer Anweisungen für Menschen besteht aus ungefähr drei Milliarden Buchstaben. Wenn auch nur ein Fehler in einer Million aufträte, würden jedes mal 3.000 Fehler auftreten, wenn sich das menschliche Genom verdoppelt. Das Genom verdoppelt sich etwa eine Million Milliarde Male im Leben aus einem befruchteten Ei. Deshalb ist es unwahrscheinlich, dass der menschliche Organismus eine so eine hohe Fehlerrate ertragen könnte. In Wirklichkeit beträgt die Fehlerrate etwa 1 in 10 Milliarden. Wie erreichen die Zellen solch eine hohe Wiedergabetreue?
"In den Zellen aller Lebewesen ist die genetische Mitteilung in der doppel-strangigen DNA enthalten. Die DNA ist so gebaut, dass sie die genetische Mitteilung genau bewahrt. Die beiden Stränge ergänzen sich gegenseitig, sind komplementär. Deshalb tragen sie die gleiche genetische Information, etwa so, wie der positive und negative Filmstreifen die gleiche Szene darstellt. Wie beim Filmstreifen, kann man auch hier den einen Strang der DNA benutzen, um den anderen wieder herzustellen. Wenn der eine Strang beschädigt wird, kann man ihn reparieren, indem man den (gegenüber liegenden, komplimentären) unbeschädigten Strang wie eine Schablone benutzt und damit den neuen Strang anfertigt. Die DNA wird routinemäßig so ähnlich verdoppelt: Zuerst werden die beiden Elternstränge an der 'Replikations-Gabel' von einander getrennt. Und jeder dieser beiden Stränge dient nun als eine Schablone, mit der die Zelle einen neuen Strang aufbaut." Radman, M. und R. Wagner (1988:24).
"Die biochemischen 'Buchstaben', die die Information in der DNA codieren, sind vier Nukleotide. Sie unterscheiden sich von den Basen, die sie enthalten. Die Basen sind Adenin, Guanin, Thymin und Cytosin, gekürzt A, G, T und C. Die Reihenfolge, in der die Nukleotide sitzen, bestimmt, was diese genetische Mitteilung bedeutet. Die Basen auf dem einen Strang paaren sich mit den Basen auf dem anderen Strang. Sie verbinden die beiden Stränge miteinander, wie die Sprossen einer Leiter. Die Paarung ist nicht zufällig: Adenin muss sich mit Thymin paaren und Guanin muss sich mit Cytosin paaren. Die Komplementarität der Basenpaare beruht also auf der Komplementarität der DNA-Stränge." (1988:25, 26).
Wann können Fehler in der DNA-Verdoppelung entstehen?
M. Radman und R. Wagner (die an die Evolution glauben), schreiben: "Fehler, die bei der DNA Synthese entstehen, können dazu führen, dass nichtkomplimentäre Basenpaare oder fehlerhafte Paarungen entstehen. Andere Arten von Fehlern können durch Umwelteinflüsse entstehen. Reparatur von Umweltschäden an der DNA (die durch Chemikalien, Strahlung und so weiter entstanden ist)... Wenn man die DNA ohne Enzyme zusammenfügt, passieren solche Fehler etwa einmal in je 100 Basen. Die enzymatischen Systeme, wie oben beschrieben, machen die Synthese 100 Millionen Male genauer, als die nichtenzymatische Synthese." (1988:26).
Warum so genau?
Warum kopiert die Zelle ihre eigene Erbinformation, ihre DNA so genau?
H. Radman und R. Wagner: "Drei verschiedene enzymatische Vorgänge sorgen für die hohe Wiedergabetreue der DNA Replikation. Der erste Vorgang entscheidet darüber, welche der vier Nukleotiden ausgewählt und an den freien Strang geheftet werden. Der zweite Vorgang "liest" die zuletzt hinzugefügten Nukleotide "Korrektur" und nimmt sie heraus, wenn sie nichtkomplimentär sind (nicht richtig zusammen passen). Der dritte Vorgang findet nach der Synthese statt. Er bessert die Fehler aus, die den ersten beiden 'Redakteuren' entgangen sind. Das Auswählen der Nukleotide und das Korrekturlesen geschieht zusammen mit der DNA Reproduktionsmaschinerie. Deshalb bezeichnet man das als einen Fehlervermeidungs-Mechanismus. Der Mechanismus, der nach der Synthese beginnt, ist ein Fehlerkorrektur-Mechanismus; man bezeichnet ihn als Reparatur nicht zusammen gehörender Basenpaare.
"Die Genauigkeit der Reproduktion beruht hauptsächlich darauf, wie genau man die richtigen Nukleotide auswählt. Das gleiche Enzym, das die Polymerisation der Nukleotiden ausführt, sorgt hier für die richtige Auswahl. Das Enzym, das man als DNA Polymerase bezeichnet, bewegt sich an der DNA Schablone (template) entlang und baut die komplementären Stränge aus dem Vorrat an Nukleotiden der Zelle zusammen. Die freien Nukleotide sind in der Form von Triphosphaten. Das heißt, sie tragen eine Schnur von drei Phosphatgruppen. Die Nukleotide müssen zu Monophosphaten gespalten werden, bevor man sie an die neuen Stränge anheften kann. Die DNA Polymerase nimmt ein Nukleotid-Triphosphat auf, spaltet es zu einem Monophasphat und heftet dieses Monophasphat dann am Ende des frei werdenden Stranges an." Radman, M., und R. Wagner (1988:26).
"Die Nukleotidauswahl beruht auf den aktiven Verbindungen zwischen konkurrierenden Reaktionen. Mit anderen Worten: Man kann irgendeine Base gegenüber irgendeiner anderen Base einfügen. Aber die korrekte Paarung ist energetisch günstiger. ... Wenn ein Nukleotid tatsächlich komplementär ist, passt es gut mit der Schablonenbase zusammen. Und der Zusatz wird stabilisiert. Wenn das Nukleotid nichtkomplimentär ist, passt es nicht gut. Die Reaktion wird umgekehrt. Und das Nukleotid wird in seine Triphosphat-Form zurückverwandelt. Die Rolle, die die Polymerase hier spielt, kann man gut mit einem blinden Koch vergleichen. Er nimmt sich irgendwelche Zutaten, schmeckt jede einzelne und entscheidet sich, ob er sie der Suppe hinzufügen oder sie wieder auf das Regal zurückstellen soll.
"Bei 100.000 richtig ausgewählten Nukleotiden wird etwa ein falsches, nichtkomplimentäres Nukleotide eingebaut. Ein Fehler, der bei diesem Vorgang nicht erkannt wird, begegnet dem zweiten Mechanismus oder der Fehlervermeidung: dem Korrekturlesen. Das Korrekturlesen wird von einer enzymatischen Aktivität ausgeführt, die entweder dazu gehört oder die mit der DNA Polymerase verbunden ist. Diese Aktivität bezeichnet man spaßhaft als 'exonukleases Korrektur lesen'... Die Exonuclease kann beide, die komplementären und nichtkomplimentären Nukleotide vom Ende des frei werdenden Stranges entfernen. Aber gewöhnlich kommt es nur dazu, wenn ein Nukleotid nichtkomplimentär ist. Wenn ein unpassendes Nukleotid eingebaut worden ist, hemmt das sehr den Einbau des nächsten Nukleotides. Und die Pause im Polymerisationsvorgang gibt der Exonuklease Zeit, das nichtkomplimentäre Nukleotid zu entfernen. Die Polymerase versucht dann wieder, für das falsche, nicht komplimentäre Nukleotid, ein richtiges, komplementäres Nukleotid zu finden.
"Unter gewöhnlichen Umstände, wenn die Nukleotide auswählt werden und die Exonuclease den genetischen Text Korrektur liest, entsteht etwa ein Fehler bei 10 Millionen Basenpaaren. Aber beide Fehlervermeidungs-Mechanismen können beeinträchtigt werden, wenn der Vorrat an Triphosphaten, der das Rohmaterial für die Synthese liefert, ungleiche Mengen von den vier Arten von Nukleotiden hat." Radman M., und R. Wagner (1988:26, 27).
"Fehlervermeidungs-Mechanismen sind einfache enzymatische Reaktionen, in denen energisch wünschenswerte Ergebnisse über weniger stabile Ergebnisse siegen. Die Fehlerkorrektur ist etwas komplizierter. Damit die enzymatische Maschinerie ein falsch eingebautes Nukleotid in der neu gebauten DNA auswechseln kann, muss es das falsche Nukleotid entdecken und entfernen und die richtige Reihenfolge neu aufbauen.
"Am meisten haben wir über die sehr genau arbeitenden Mechanismen der DNA-Reproduktion durch Experimente mit Bakterien gelernt. Wie weit kann man dieses Wissen bei komplexeren Organismen anwenden? Diese beiden Fehlervermeidungs-Mechanismen gibt es wahrscheinlich in fast allen Organismen. Und sie funktionieren dort wahrscheinlich genau so. Es gibt auch reichlich Beweise dafür, dass die falsch eingebauten Nukleotide auch in der Hefe, in Pilzen und Fruchtfliegen, sowie in Fröschen und Säugetieren ausgewechselt werden.
"Doch die meisten Fehler entstehen nicht während der Reproduktion, sondern bei der genetischen Rekombination. DNA-Stränge verschiedener Abstammung werden dann zwischen den Molekülen ausgetauscht." Radman, M. und R. Wagner (1988.29).
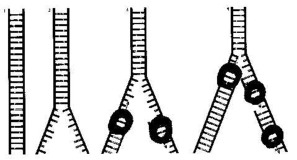
Die Verdopplungsgabel öffnet das zwei-strangige DNA-Molekül (1) wie einen Reißverschluss (2). Synthetisierende Enzyme, die DNA Polymerasen, heften sich an den frei liegenden Stamm-Strang. Und die Synthese der zwei frei werdenden Stränge verläuft dann in der entgegengesetzten Richtung (3). Die Polymerase auf der einen Seite verläuft entlang des sich öffnenden Stranges. Auf der anderen Seite müssen neue Polymerasen sich dicht an der Gabel anheften, um den Strang zwischen der Gabel zu synthetisieren und an der Stelle, wo sich die letzte Polymerase angeheftet hat (4). Nach M. Radman et al. (1988:26).
![]()
Korrekturlesen geschieht durch die Exonclusease-Tätigkeit, die mit der Polymerase verbunden ist. Die Exonuclease entfernt Nucleotide, die dem Strang hinzugefügt worden sind. Wenn ein falsches Nukleotid am letzten Basenpaar eingebaut worden ist, verlangsamt das den Einbau der nächsten Nukleotide (1). Die Exonuclease (ein Enzyme) kann dann einspringen (2). Die Polymerase sucht dann weiter nach dem passenden Teilchen (3). Aus: M. Radman et al. (1988:28). Wenn DNA ohne Enzyme aufgebaut wird, entsteht ein Fehler bei je 100 Basenpaaren. Wenn Enzyme dabei sind, ist die Synthese (der Aufbau) 10 Millionen Male genauer als ohne Enzyme. Dann entsteht nur ein Fehler bei 10 Milliarden Basenpaaren.
Genetischer Code und der Übersetzungsapparat: Ihr Ursprung
Die lebende Zelle hat einen genetischen Code und einen Übersetzungsapparat. Warum existieren sie? Warum sind sie entstanden? Und warum bedeutet ein bestimmtes Nukleotid Codewort (DNA-Triplet) etwas? Wie sind der DNA-Code und der Protein-Code physisch miteinander verbunden?
James Darnell, Rockefeller Universität, Harvey Lodish, Massachusetts Institut für Technologie, und David Baltimore, Rockefeller Universität, glauben alle an die Evolution. Aber sie geben in ihrem Lehrbuch Molecular Cell Biology (1990:1131), unter der Überschrift "Der Ursprung des Genetischen Codes und des Übersetzungsapparates" zu:"
"Bei der vorzelligen Evolution musste man zwei verschiedene, aber zusammenhängende Probleme lösen, damit die Nukleinsäure Information speichern kann, die vorschreibt, wie man Proteine herstellt. Zuerst musste man eine Übereinstimmung zwischen der linearen Ordnung in dem einen Polymer und der linearen Ordnung in dem anderen herstellen. Das heißt, ein Code musste entstehen. Dann musste man herausfinden, wie man die eine lineare Ordnung in die andere übersetzt. Wir wissen, dass in allen Zellen der heutige drei Buchstaben Nukleotid-Code in der mRNA die erste dieser Anforderungen erfüllt. Und dass die tRNA im Ribosom das übersetzt. Doch genau wie der Nukleotid-Code die 'Wörter' ausgewählt hat, werden wir wahrscheinlich nie herausfinden. Weil es keine bekannte chemische Komplementarität (Verbindung) zwischen den drei Nukleotiden eines Codon und der Aminosäure gibt, die zu ihm gehört."
"Eine ausführliche Theorie der Evolution müsste erklären, wie aus der primitiven Oligonucleotid-Oligopeptid Wechselwirkung ein arbeitendes Übersetzungssystem geworden ist. Doch das wissen wir überhaupt nicht. ... Wir haben schon früher erwähnt: Absolute Schlüsse über die Natur der frühesten Gene oder der frühesten Zellen mögen nie möglich sein." Darnell, J. et al. (1990:1056, 1071).
RNA-Molekül zuerst
Evolutionisten haben versucht, aus ihren Schwierigkeiten herauszukommen, indem sie sagen: Die erste Zelle auf der Erde ist in der chemischen Ursuppe aus einem RNA Molekül entstanden. - Stimmt das? Ist das wissenschaftlich?
Robert Shapiro ist Professor für Chemie an der Universität von New York, USA Er berichtet: "Die Entdeckung katalytischer Fähigkeit in der RNA hat Spekulationen frischen Auftrieb gegeben, dass diese RNA beim Ursprung des Lebens eine wichtige Rolle gespielt hat. Die Antwort zu dieser Frage beruht darauf, ob die präbiotische Oligonucleotid-Synthese glaubwürdig ist, statt auf den Eigenschaften des Endproduktes. Man hat viele Behauptungen veröffentlicht, um zu beweisen, dass die Bestandteile der RNA in großer Menge auf der präbiotischen Erde vorhanden waren. ... Die Beweise, die wir jetzt haben, beweisen nicht, dass Ribose auf der präbiotischen Erde vorhanden war, außer vielleicht für kurze Zeit, in niedriger Konzentration als Teil einer komplexen Mischung, und unter Bedingungen, die sich nicht für die Nukleosid-Synthese eigneten.
"Man hat angedeutet, dass 'das Leben mit einer RNA-Welt angefangen hat' (Gilbert, 1986), in der nur replizierende RNA-Arten und Ribonukleotide vorhanden waren (Scharf, 1985). Gilbert meint: 'Die erste Phase der Evolution hat mit RNA-Molekülen begonnen. Sie führen die katalytischen Aktivitäten aus, die notwendig sind, um (die verschiedenen Teile) in einer Nukleosid-Suppe zusammenzusetzen.'" (1988:71).
"Viele Wissenschaftler und Schriftsteller, die sich mit dem Ursprung des Lebens befassen, haben angenommen, dass die notwendigen Teile für die Herstellung der RNA auf der präbiotischen Erde in großen Mengen vorhanden waren. Eigen und Schuster (1978), zum Beispiel, gaben an: 'Wir nehmen hier einfach an, als der Selbstaufbau begann, dass alle Arten energiereichen Materials überall vorhanden waren, besonders: Aminosäuren in verschiedenen Mengen, Nukleotide, die man für die vier Basen, A, U, C, G braucht, Polymere beider Klassen... welche mehr oder weniger zufällige Reihenfolgen haben.'
"Die selben Autoren (Eigen und Schuster, 1982) schrieben später: 'Die Bausteine der Polynukleotide - die vier Basen, Ribose und Phosphat - bilden Vorräte, die sich immer wieder auffüllen. Aus (deren Bestandteilen) werden dann Polymere hergestellt, auch Polypeptide und Polynukleotide. Und Kuhn und Waser (1981) meinten: 'Die wichtigsten Bestandteile unseres Modells für den Ursprung und die frühesten Schritte des Lebens sind Aminosäuren, Ribose und die Nukleotid Basen G, C, A, und U. Diese Substanzen waren vermutlich auf dem urzeitlichen Planeten reichlich vorhanden. Und sie haben sich vielleicht in bestimmten Gebieten durch natürliche Konzentrationsvorgänge, wie Verdampfung aus einer wässrigen Lösung und Eindickung des Rückstandes, angesammelt oder durch Adsorption und Desorption.'
"Ergebnis: Die Beweise, die wir jetzt haben, stützen nicht die Ansicht, dass Ribose auf der präbiotischen Erde vorhanden war, außer vielleicht für kurze Zeit, in niedriger Konzentration, als Teil einer komplexen Mischung, unter Umständen, die für die Nukleosidsynthese ungeeignet sind. ... Man sollte jetzt eine andere Möglichkeit ernsthaft erwägen: dass die RNA am Anfang des Lebens nicht vorhanden gewesen ist, sondern dass sie zuerst biosynthetisch erzeugt worden ist..." Shapiro, R. (1988:73, 74).
Die Zelle, wie komplex
Wie komplex ist die bakterielle Zelle? Wie gut kennt man sie jetzt?
James D. Watson hat zusammen mit Francis Crick und Maurice Wilkins im Jahre 1962 den Nobelpreis erhalten. Er arbeitet jetzt am Cold Spring Harbor Laboratorium. James D. Watson und seine Mitarbeiter erklären in ihrem Lehrbuch Molecular Biology of the Gene, unter der Überschrift: "Selbst kleine Zellen sind sehr komplex": "Wir müssen sofort zugeben, das wir die Struktur einer Zelle niemals so verstehen werden, wie wir das Wasser- oder Traubenzucker-Molekül verstehen. Die dreidimensionale Struktur der meisten zellularen Proteine bleibt ungelöst. Und die Stelle, an der sie sich innerhalb der Zellen befinden, bleibt oft recht unklar." (1987:1019).
Und unter der Überschrift "Bakterielle Zelle: eine sehr genau arbeitende Maschine", schreiben sie: "Der Tag ist längst vergangen, wo man sich fragte, ob man mehr braucht, als die Gesetze der Chemie, damit die bakterielle Zelle richtig arbeitet. Wir betrachten jetzt das Bakterium als eine außergewöhnlich hochentwickelte Anlage zusammenhängender Moleküle, die harmonisch auf sehr voraussagbare Weisen zusammen funktionieren, um den Wuchs und das selektive Überleben von mehreren ihrer Art zu sichern. Der Kern dieser bemerkenswerten, fast wie ein Uhrwerk laufenden Maschinen sind die DNA Moleküle. Sie verschlüsseln, ganz genau, Sätze von Befehlen. Sie bewirken, dass die Moleküle dann das tun, was nötig ist, um mit dem, was an Nahrung vorhanden ist, zurecht zu kommen. ... Genau, wie sich jede der 20 Aminosäuren mit ihrem Codon (oder Codonen) gepaart hat, weiß man nicht." Watson, J. D. et al. (1989:122, 123, 459).
Bernd-Olaf Küppers
Wie kompliziert ist eine einfache Bakterienzelle und die Zelle des Menschen? Wie viel Erbinformation enthalten sie? Was war nötig, um sie zu erdenken und zu bauen? Was brauchen sie, um zu funktionieren? - Bernd-Olaf Küppers ist Mitarbeiter am Max-Planck-Institut für biophysikalische Chemie in Göttingen. Nobelpreisträger Manfred Eigen ist der Direktor dieses Instituts. Küppers Hauptarbeitsgebiet: die Entstehung des Lebens.
Bernd-Olaf Küppers, ein Evolutionist, schreibt: "Selbst eine ‚einfache‘ Bakterienzelle ist in ihrem materiellen Aufbau noch ungeheuer komplex. ... Das Innenleben einer Zelle gleicht einer vollautomatisierten chemischen Fabrik, in der laufend kleinere Moleküle ineinander umgewandelt und biologische Makromoleküle aufgebaut werden. Hierbei ist jeder Reaktionsschritt minuziös geregelt mit dem einzigen Ziel, das System reproduktiv zu erhalten." (1978).
Wie viel Information enthält eine Bakterienzelle? Wie viel die eines Menschen?
B.-O. Küppers: "Die genetische Information eines Bakteriums zum Beispiel umfasst etwa vier Millionen molekulare Symbole, die des Menschen über eine Milliarde. Auf unsere Sprache übertragen, würde der Bauplan eines Bakteriums etwa einen Umfang eines 1.000 Seiten starken Buches einnehmen, der Bauplan des Menschen bereits den Umfang einer 1.000 Bücher umfassenden Bibliothek. Die Reproduktionszeit eines Bakteriums dauert in der Regel nur 20 Minuten. Innerhalb dieser Zeit müssen sein Bauplan Symbol für Symbol abgeschrieben und die darin verschlüsselten Anweisungen für den Bauplan für den Aufbau einer neuen Bakterienzelle ausgeführt werden."
Aber wer liest den Bauplan ab und führt die Syntheseanweisungen aus?
"Die Analyse lebender Systeme hat gezeigt, dass dafür wieder eine einheitliche Klasse von biologischen Makromolekülen verantwortlich ist: die Proteine. Diese sind die Funktionsträger lebender Systeme. In Form hochspezialisierter molekularer Maschinen erfüllen sie alle wesentlichen Aufgaben, wie Stoffaufbau, Energieumsatz, Synthese und Regelung. Insbesondere gibt es unter den Proteinen molekulare Kopiermaschinen, die den genetischen Bauplan symbolgetreu vervielfältigten." (1978).
Das heißt: Selbst die einfachste Bakterienzelle ist noch so kompliziert wie eine vollautomatische chemische Fabrik. Ihre Erbinformation, in menschlicher Sprache ausgedrückt, würde ein 1.000 Seiten dickes Buch füllen. Die Zelle liest und kopiert all diese Erbinformation und baut danach dann in nur etwa 20 Minuten eine neue Bakterienzelle! - Kann das wirklich nur durch ein ‚Glasperlen-Spiel‘ entstanden sein, oder durch einen dialektischen Kampf, in dem sich die Materie qualitativ verändert?
Evolutionist B.-O. Küppers: "Offenbar ist die Wahrscheinlichkeit für die Zufallssynthese eines ‚Urgens‘ umgekehrt proportional zur Zahl seiner kombinatorischen Sequenzalternativen. Im einfachen Fall der Bakterienzelle beträgt diese Zahl bereits 102.000.000.000. Dies ist eine 1 mit zwei Millionen Nullen!
"Es ist absolut unwahrscheinlich, dass in einem molekularen Roulettspiel der Bauplan selbst der einfachsten Zelle entstehen könnte. Ebenso wenig würde man durch bloßes Zusammenschütteln von Buchstaben ein vollständiges Lehrbuch der Biologie erhalten." (1978).
Ergebnis und Fragen
Wir haben jetzt herausgefunden: Das "Innenleben" einer "einfachen" Bakterienzelle ist "ungeheuer komplex", wie eine "vollautomatisierte chemische Fabrik". Die Erbinformation eines Bakteriums enthält etwa 4.000.000 molekulare Symbole oder Buchstaben. In der Sprache des Menschen ausgedrückt: Die Erbinformation der Bakterienzelle würde ein 1.000 Seiten dickes Buch füllen. Diese ganze Information reproduziert sie in nur 20 Minuten, Symbol um Symbol, wenn sie eine neue Bakterienzelle aufbaut.
Entsteht eine automatische chemische Fabrik von selbst durch Zufallsmutation und Selektion? Oder durch ein Glasperlenspiel? Durch Naturgesetze? Oder durch einen dialektischen Kampf? Entsteht so ein 1.000-Seiten starkes Buch? - Wohl kaum. - Zuerst müssen begabte Chemiker und Ingenieure die automatische chemische Fabrik erdenken und bauen. Ein Mensch schreibt zuerst ein Buch. Die Buchstaben, Wörter, Sätze und Kapitel sind nicht durch ein Glasperlenspiel dort hineingekommen, durch Naturgesetze, oder durch einen qualitativen Wechsel in einem dialektischen Kampf. Das ist nur reines Wunschdenken, nicht ernsthafte Wissenschaft.
Das Virus: fehlendes Bindeglied
Einige glauben ernsthaft, das Virus sei das fehlende Bindeglied zwischen der anorganischer Materie und der ersten bakteriellen Zelle. - Stimmt das? Ist das wissenschaftlich?
Jim Brooks, britischer Biochemiker, schreibt über das Virus: "Viren sind keine frei lebenden Organismen (können sich nicht selbst am Leben erhalten). Man kann sie nicht als lebend betrachten. Sie sind keine primitiven, sondern sehr hoch entwickelte Parasiten, die auf Zellen angewiesen sind. ... Man meint oft, die Viren stünden an der Schwelle des Lebens. Aber sie haben sich offensichtlich nicht in der chemischen Evolution aus einfacheren Formen entwickelt. Das sind entweder Zellen, bei denen etwas falsch gelaufen ist, oder sie sind entartete Formen höherer Lebewesen ". (1985:96).
Ergebnis
Die Atome, die die vier verschiedenen Nukleinsäuren bilden, mit ihrer bestimmten dreidimensionalen Form, wissen nichts von DNA-Strängen in der lebenden Zelle. Und die Atome in den 20 Aminosäuren, welche die Buchstaben des Proteins verschlüsseln, wissen nichts über die verschiedenen Arten von Proteinen in der lebenden Zelle. Und das Triplet des Nukleinsäure-Code und die Aminosäuren des Protein-Codes sind physisch überhaupt nicht miteinander verbunden. - Warum nicht? - Weil ihre Bedeutung geistig, nicht-materiell ist.
Information kann nicht durch Zufall entstehen. Information wird auch nicht zufällig entstehen, wenn 1.000 Affen Millionen von Jahren auf der Schreibmaschine schreiben. Das Shakespeare-Sonett, das Affen unabsichtlich geschrieben haben, ist überhaupt keine Information, obwohl es dem Leser wie das Original erscheinen mag. Für den Neodarwinisten ist dies die einzige Art von Information, die es auf der Welt gibt.
Alle grundlegenden Lehren der Evolution haben wir jetzt gründlich widerlegt. Sie haben überhaupt nichts mit ernsthafter Naturwissenschaft zu tun. Die Evolutionshypothese, wie jetzt allgemein auf der Welt gelehrt, ist nur eine fromme Mythe. Sie ist ein alter religiöser Glaube im weißen Mantel der modernen Wissenschaft. Die alten Sumero-Babylonier glaubten schon, das Leben auf der Erde habe sich von selbst aus dem Schlamm des Euphrat und Tigris entwickelt. Sie glaubten schon vor etwa 4.000 Jahren an die chemische Evolution. Und die alten Ägypter glaubten, das Leben auf der Erde sei von selbst aus dem Wasser und Schlamm des Nils entstanden. - Information, Design, Planung, Zweck und Mathematik in der lebenden Zelle beweisen, dass sie eine intelligente Person erdacht und erschaffen hat, der Schöpfer.